
참고자료
아래의 글은 Gabriel Tseng 의 [Gradient Boosting and XGBoost] (https://medium.com/@gabrieltseng/gradient-boosting-and-xgboost-c306c1bcfaf5)를 번역한 글입니다.
참고 : 이 게시물은 원래 Canopy Labs 웹 사이트에 게시된 글입니다.
XGBoost는 강력하고, 번개 같이 빠른 기계 학습 라이브러리입니다. 그것은 일반적으로 Kaggle 대회 (그리고 다른 여러 가지 것들)를 이기기 위해 사용됩니다. 그러나 이것은 매개 변수의 수가 많아서 접근하기 힘든 알고리즘이며, 모두가 무엇을하는지 명확하지 않습니다.
XGBoost가하는 일을 설명하는 많은 게시물이 이미 존재하지만 많은 사람들이 그래디언트 증폭, 그래디언트 증가 트리 및 XGBoost를 혼동합니다. 이 게시물의 목적은 이러한 개념을 명확히하기 위한 것입니다. 또한 XGBoost의 하이퍼 파라미터가 덜 위협적이 되도록 하기 위해, 이 포스트는 (설명서보다 조금 더 자세히) scikit-learn API에서 노출된 하이퍼 파라미터가 정확히 무엇을 하는지 탐구한다
내용:
-
그래디언트 증가
-
그래디언트 증가 트리
-
극한 그래디언트 증가
1. Gradient Boosting
만약 당신이 이것을 읽고 있다면, 당신은 확률적 경사 강하(SGD)에 익숙할 것이다. (그렇지 않다면, 나는 앤드류 Ng의 이 비디오를 강력히 추천한다. 그리고 나머지 과정들은 무료로 보실수 있다..) 다음과 같은 경우:
그래디언트 부스팅은 확률적 그래디언트 디센트와 다른 문제를 해결합니다.
SGD를 이용하여 모델을 최적화할 때, 모델의 구조는 고정되어 있다. 따라서 최적화를 시도하는 것은 모형의 P 매개변수(로지스틱 회귀에서,,이것은 가중치일 것이다). 수학적으로, 이것은 다음과 같이 보일 것이다
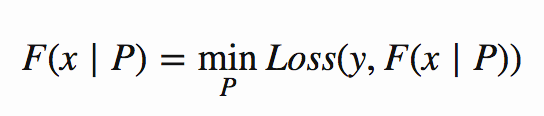
즉, 나는 내 함수 F에 가장 좋은 매개변수 P를 찾으려고 하고 있는데, 여기서 ‘최적’은 가능한 가장 작은 손실로 이어진다는 것을 의미한다( F(x∣P)의 수직 선은 파라미터 P를 찾으면 해당 파라미터를 사용하여 주어진 F의 출력을 계산한다는 것을 의미한다.)
그래디언트 부스팅은 이 고정된 구조를 가정하지 않는다.. 실제로 그래디언트 부스팅의 전체적인 점은 데이터를 가장 근사하게 만드는 함수를 찾는 것입니다. 다음과 같이 표현됩니다.
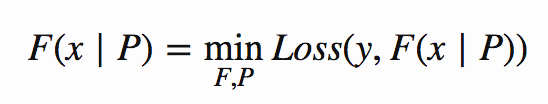
변경된 유일한 점은 이제 최상의 매개 변수 P를 찾는 것 외에도 최상의 함수 F를 찾고 싶다는 것입니다. 이 작은 변화는 문제에 많은 복잡성을 가져온다; 이전에 내가 최적화하던 파라미터의 수는 고정되어 있었지만(나의 로지스틱 회귀 모델은 훈련을 시작하기 전에 정의되어 있다), 이제, 함수 F가 바뀌면 최적화 과정을 거치면서 바뀔 수 있다.
분명히, 가능한 모든 함수와 매개변수를 검색하는 것은 너무 오래 걸릴 것이기 때문에, 그래디언트 부스팅 간단한 함수를 많이 사용하여 최상의 함수 F를 찾아서 함께 추가합니다.
SGD가 단일 복합 모델을 교육하는 경우 그래디언트 증폭은 간단한 모델의 앙상블을 교육합니다.
이 방법은 다음과 같다.
아주 간단한 모델 h를 취해서 그것을 어떤 데이터 (x, y)에 맞춥니 다.
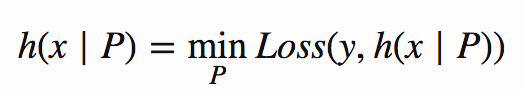
내가 두 번째 모델을 훈련할 때, 나는 분명히 이 첫 번째 모델 h와 같은 패턴을 데이터에서 발견하는 것을 원하지 않는다; 이상적으로, 이 첫 번째 예측의 오류를 개선할 것이다. 이것이 영리한 부분(그리고 ‘그래디언트’ 부분): 이 예측에는 약간의 오류가 있을 것이다, 제가 적합하게 될 다음 모델은 예측에 대한 오차의 기울기, ∂Loss / ∂ be에있을 것입니다.
왜 이것이 영리한 지 생각해 보려면, 평균 제곱 오차를 고려하십시오.
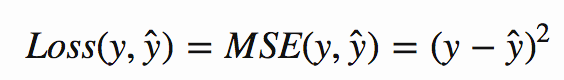
이 그래디언트를 계산하면,
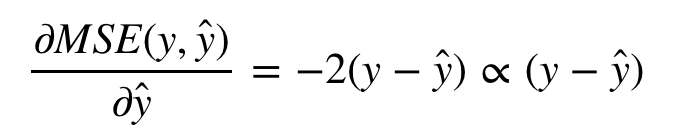
하나의 데이터 포인트에 대해 y = 1 및 ŷ = 0.6 인 경우이 예측의 오류는 MSE (1,0.6) = 0.16이고 모델의 새 타겟은 (y-ŷ) = 0.4의 그래디언트가됩니다. 이 목표에 대한 모델 교육,
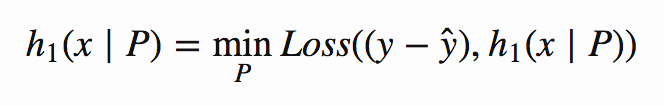
여기서 y=1(그리고 이전 모델의 경우 ŷ =0.6)과 동일한 데이터 포인트에 대해 모델은 0.4의 목표치에 맞게 훈련되고 있다. ŷ_1=0.3을 반환한다고 하자. 그래디언트 부스팅의 마지막 단계는 이 모델들을 함께 추가하는 것이다. 내가 교육한 두 가지 모델에 대해(그리고 이 특정 데이터 지점에 대해),
이제 y = 1 인이 동일한 데이터 포인트 (이전 모델의 경우 ŷ = 0.6 인 경우 모델은 0.4의 목표에 대해 학습 중입니다.)ŷ_1 = 0.3을 반환한다고 가정합니다. 그래디언트 증폭의 마지막 단계는 다음과 같습니다. 이 모델들을 함께 추가 할 수 있습니다. (그리고이 특정 데이터 포인트에 대해) 필자가 훈련 한 두 모델의 경우,
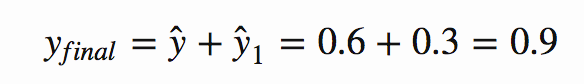
첫 번째 모델의 손실 예측과 관련하여 오류의 구배에 대한 나의 두 번째 모델을 훈련시킴으로써, 나는 첫 번째 모델의 오류를 수정하는 것을 가르쳤다. 이것은 경사도 부양의 핵심이며, 많은 단순한 모델들이 데이터에 더 잘 맞도록 서로의 약점을 보완할 수 있게 하는 것이다.
오류의 첫번째 모델에서 손실 예측에 대한 그래디언트로 나의 두번째 모델을 훈련함으로써, 첫 번째 모델의 실수를 수정하도록 가르쳐 왔습니다. 이것은 그래디언트 증폭의 핵심이며 많은 단순 모델이 서로의 약점을 보완하여 데이터에 더 잘 맞도록합니다.
나는 2 개의 모델에서 멈출 필요가 없다; 계속해서 새로운 모델을 모델의 업데이트 된 합계의 오류 그래디언트 에 맞추어 계속 반복 할 수 있습니다.
여기서 흥미로운 점은 그 핵심에서 구배 부스팅은 F 함수를 최적화하는 방법이지만 h에 대해서는 별로 관심이 없다는 것이다(h의 최적화에 대해서는 아무것도 정의되지 않았기 때문에). 이는 어떤 기본 모델 h를 사용하여 F를 구성할 수 있다는 것을 의미한다.
여기에서 흥미로운 점은 핵심에서 그래디언트 부스팅은 함수 F를 h에 대해서는 별로 관심이 없다는 것이다(h의 최적화에 대해서는 아무것도 정의되지 않았기 때문에). 이것은 임의의 기본 모델 h가 F를 구성하는 데 사용될 수 있음을 의미합니다.
2. 그래디언트 부스트 트리
그래디언트 부스트 트리는 단순 모델 h가 의사 결정 트리 인 특별한 경우를 고려합니다. 시각적으로 (이 다이어그램은 XGBoost의 설명서에서 가져온 것입니다)) :
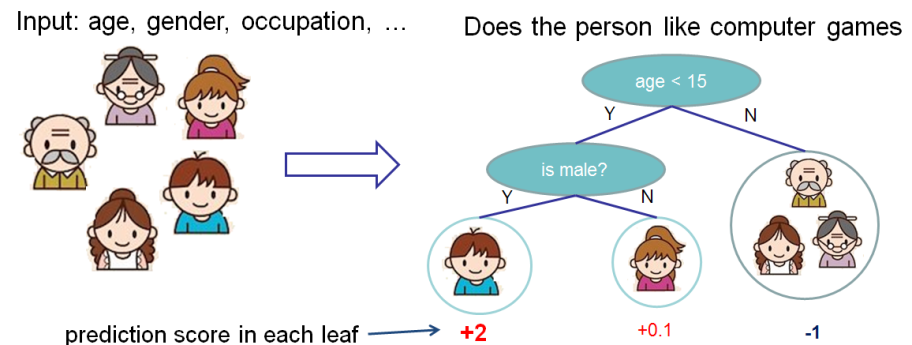
이 경우 파라미터 P에는 두 가지 종류가 있다. 즉, 각 잎의 가중치, w, 각 트리의 잎 T의 수이다(위 예에서는 T=3과 w=[2, 0.1, -1]).
의사결정 트리를 세울 때, 과제는 현재의 잎을 어떻게 쪼개야 하는가를 결정하는 것이다. 예를 들어, 위의 그림에서 어떻게 하면 (나이 > 15) 잎에 다른 층을 추가할 수 있을까? 이를 위한 ‘욕심’ 방법은 나머지 특징(그러므로 성별과 직업)에 대해 가능한 모든 분열을 고려하고 각 분리에 대한 새로운 손실을 계산하는 것이다. 그런 다음 가장 많이 손실을 줄이는 트리를 선택할 수 있다.
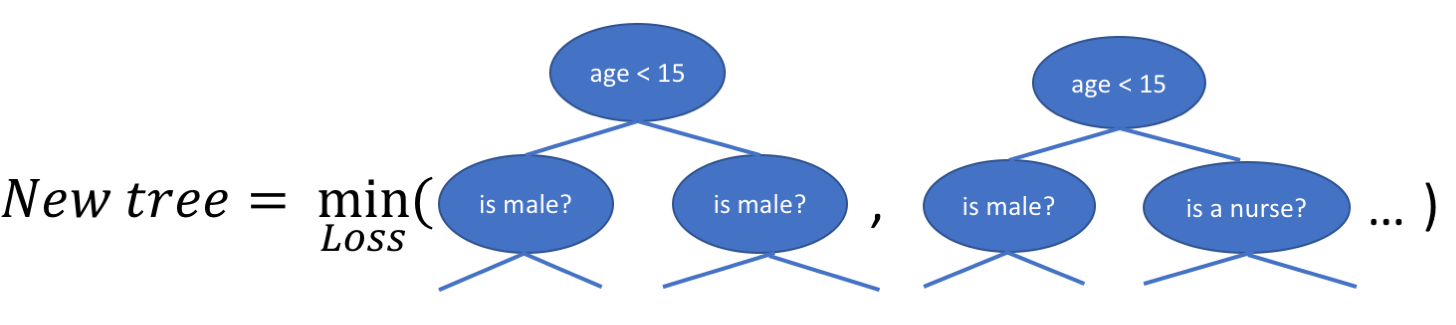
새로운 나무 구조를 찾는 것 외에도, 손실을 최소화하도록 각 노드의 가중치도 계산할 필요가 있다. 트리 구조가 이제 고정되었으므로, 이것은 손실 함수를 0으로 설정하여 분석적으로 수행할 수 있다(추출에 대한 부록 참조, 그러나 당신은 다음 사항과 함께 남는다).
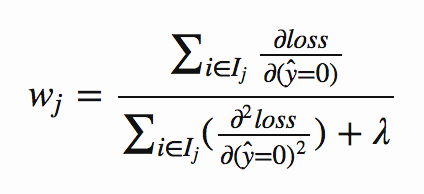
여기서 Ij는 리프에서 모든 인스턴스 ((x, y) 데이터 점)를 포함하는 집합이고, wj는 리프 j에서의 가중치입니다. 이것은 그보다 더 위협적으로 보입니다. 어떤 직감에 있어, 손실 = MSE = (y, ŷ) ^ 2를 고려하면 ŷ = 0 일 때 첫 번째와 두 번째 그래디언트를 취합니다.
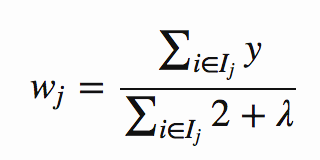
이것은 의미가 있습니다. 가중치는 사실상 각 잎에서 실제 레이블의 평균이됩니다 (λ 상수로부터 일부 정규화 됨).
3. XGBoost (및 그 하이퍼 파라미터)
XGBoost는 그래디언트 가 증가 된 트리를 가장 빠르게 구현 한 것입니다.
이는 그래이디언트가 증가 된 나무의 주요 비효율 중 하나를 다루어 줌으로써, 새로운 가지를 만들기 위해 가능한 모든 분열의 잠재적 손실을 고려한다.(특히 수천 개의 특징이 있고 따라서 수천 개의 쪼개질 수 있는 경우를 고려하는 경우) XGBoost는 리프 내의 모든 데이터 포인트에 걸친 형상의 분포를 살펴보고 이 정보를 사용하여 가능한 형상 분할의 검색 공간을 줄임으로써 이러한 비효율성에 대처한다.
XGBoost는 몇 가지 정규화 기법을 구현하지만, 이 속도 향상은 라이브러리의 가장 유용한 기능이므로 많은 하이퍼 매개 변수 설정을 신속하게 조사 할 수 있습니다. 튜닝 할 하이퍼 파라미터가 많이 있기 때문에 유용합니다. 거의 모든 제품은 과적합을 제한하도록 설계되었습니다 (기본 모델이 얼마나 단순하더라도 수천 개의 모델을 함께 묶어두면 과적합 됩니다).
내가 XGBoost와 함께 일하기 시작했을 때, 하이퍼 파라미터 리스트는 나에게 엄청나게 위협적이어서, 지금까지 모델을 훈련할 때 가장 중요하게 여겼던 4가지 파라미터에 대해 논의할 것이다(부록의 모든 파라미터에 대한 설명서보다 조금 더 자세한 설명을 하려고 했다).
내가 XGBoost로 작업하기 시작했을 때 하이퍼 파라미터 목록이 너무 힘들었 기 때문에 지금까지 모델을 훈련 할 때 가장 중요한 4 가지 매개 변수에 대해 논의 할 것입니다. (필자는부록의 모든 파라미터에 대한 설명서보다 조금 더 자세한 설명을 하려고 했다).
하이퍼 파라미터의 수를 제한하려는 동기는 XGBoost가 조정할 수있는 모든 하이퍼 매개 변수로 임의의 그리드 / 무작위 검색을 수행하면 검색 공간을 빠르게 폭발시킬 수 있다는 것입니다. 나는 아래 4개부터 시작해서, 내가 아직 너무 잘 맞지 않을 때만 다른 것에 뛰어들면 도움이 된다는 것을 알았다..
3.a. n_estimators (및 조기 정지)
이것은 얼마나 많은 하위 트리가 훈련 될 것인가입니다. 나는 일찍 멈추기를 소개하는 것이 당신이 과적합을 피하기 위해 할 수있는 가장 중요한 일이기 때문에 이것을 먼저 쓴다. 이를 위한 동기는 XGBoost가 학습 데이터를 기억하기 시작하고 검증 세트에 대한 성능이 나 빠지게된다는 것입니다. 이 시점에서, 여러분은 더 많은 나무들을 훈련시키는 것을 멈추고 싶어한다.
조기 정지를 사용하면 XGBoost가 최종 모델(검증 점수가 가장 낮은 모델과 대조적으로)을 반환하지만, 최상의 모델은 이 최종 모델에서 교육을 받은 추가적 적합 하위 트리에서 제외되므로 이 방법은 문제가 없다는 점에 유의하십시오. trainedmodel을 사용하여 최상의 모델을 격리할 수 있다.다음과 같이 예측 방법에서 bestntree_limit.
조기 정지를 사용하면 XGBoost가 최종 모델(검증 점수가 가장 낮은 모델과 대조적으로)을 반환하지만, 그러나 최상의 모델은 이 최종 모델에서 훈련 된 추가 초과 모델 하위 트리를 뺀 값이므로 괜찮습니다. 다음과 같이 predict 메소드에서 trainedmodel.bestntree_limit을 사용하여 최상의 모델을 분리 할 수 있습니다.
results = bestxgbmodel.predict(xtest, ntreelimit=bestxgbmodel.bestntreelimit)
sklearn의 GridSearchCV와 같은 매개 변수 탐색기를 사용하는 경우 bestntreelimit를 사용하는 채점 방법을 정의해야합니다.
def bestntreescore(estimator, X, y):
"""
This scorer uses the bestntreelimit to return
the best AUC ROC score
"""
try:
ypredict = estimator.predictproba(X,
ntreelimit=estimator.bestntreelimit)
except AttributeError:
ypredict = estimator.predictproba(X)
return rocaucscore(y, ypredict[:, 1])
3.b. 최대 _ 깊이
개별 트리 h가 성장할 수 있는 최대 트리 깊이. 기본값 인 3을 사용하는 것이 좋은 출발점이며, 상당히 복잡한 데이터의 경우에도 max_depth가 5 이상일 필요는 없습니다.
3.c. 학습률
각 가중치 (모든 나무에서)에 이 값이 곱해 지므로
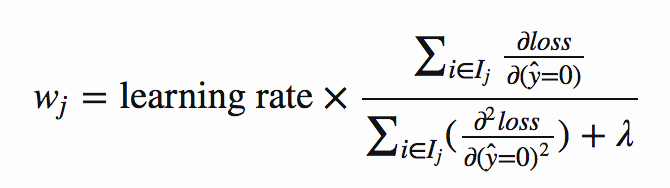
나는 학습률을 줄이면 모델의 성능이 향상된다는 것을 발견했다. (그러나 훈련 시간은 더 느리게 이어졌다).
그래이언트가 증가 된 나무의 추가 특성으로 인해, 나는 로컬 네트워크에서 신경망 (또는 확률적 경사하강법을 사용하는 다른 학습 알고리즘)보다 훨씬 작은 문제가되는 것을 발견했습니다.
3.d. regalpha 및 reglambda
손실 함수는 다음과 같이 정의됩니다.
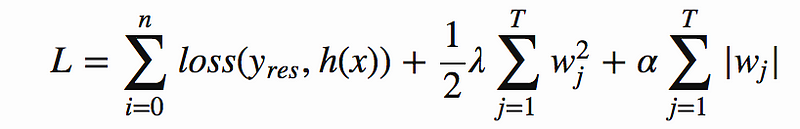
다른 매개 변수는 유용하며 위의 용어가 정규화에 도움이 되지 않을 경우 검토할 가치가 있다는 점에 유의하십시오. 하지만, 나는 모든 하이퍼 파라미터들을 탐험하는 것은 검색 공간을 폭발시킬 수 있다는 것을 발견했고, 그래서 이곳이 시작하기에 좋은 곳이다.
regalpha 및 reglambda는 L1 및 L2 정규화 조건을 제어합니다.이 경우 리프의 가중치가 얼마나 극단적으로 제한 될 수 있습니다.
이 두 정규화 용어는 가중치에 다른 영향을 미칩니다. L2 정규화 (람다 용어로 제어 됨)는 가중치를 낮추고 L1 정규화 (알파 용어로 제어)는 희소성을 조장합니다. 따라서 가중치가 0이되도록 유도합니다. 이것은 당신이 특징 선택을 원하는 로지스틱 회귀 분석과 같은 모델에서 도움이 되지만 의사결정 트리에서는 이미 우리의 특징을 선택했기 때문에 그들의 가중치를 0으로 하는 것은 큰 도움이 되지 않는다. 이러한 이유로, 나는 규칙화할 때 높은 람다 값과 낮은 (또는 0) 알파 값을 설정하는 것이 가장 효과적이라는 것을 알았다
다른 매개 변수는 유용하며 위의 용어가 정규화에 도움이 되지 않을 경우 검토할 가치가 있다는 점에 유의하십시오. 하지만, 나는 모든 하이퍼 파라미터들을 탐험하는 것은 검색 공간을 폭발시킬 수 있다는 것을 발견했고, 그래서 이곳이 시작하기에 좋은 곳이다..
결론
다행스럽게도 그래디언트 증폭이 어떻게 작동하는지, XGBoost에서 그래디언트 증가 트리가 구현되는지, XGBoost를 사용할 때 어디서부터 시작해야하는지에 대한 기본적인 이해를 얻었기를 바랍니다.
행복한 부스팅!
Sources
- T. Chen, C. Guestrin, XGBoost: A Scalable Tree Boosting System, 2016
- J. Friedman, Greedy Function Approximation: A Gradient Boosting Machine 1999
- A. Ihler, Ensembles: Gradient Boosting Youtube video, 2012
참조.
다른 하이퍼 파라미터에 대한 자세한 정보와 가중치를 얻으려면 부록에서 확인하십시오.